1Worcester Polytechnic Institute, USA,2Tohoku University, Japan3Boston University, USA*First co-author, project leader†First co-author, responsible for experiments on point cloud completion‡First co-author, responsible for experiments on few-shot classification
International Conference on Learning Representations (ICLR) 2025
Set-to-set matching aims to identify correspondences between two sets of unordered items by minimizing a distance metric or maximizing a similarity measure.
Traditional metrics, such as Chamfer Distance (CD) and Earth Mover's Distance
(EMD), are widely used for this purpose but often suffer from limitations like
suboptimal performance in terms of accuracy and robustness, or high computational costs - or both. In this paper, we propose an effective set-to-set matching
similarity measure, GPS, based on Gumbel prior distributions. These distributions
are typically used to model the extrema of samples drawn from various distributions. Our approach is motivated by the observation that the distributions of
minimum distances from CD, as encountered in real-world applications such as
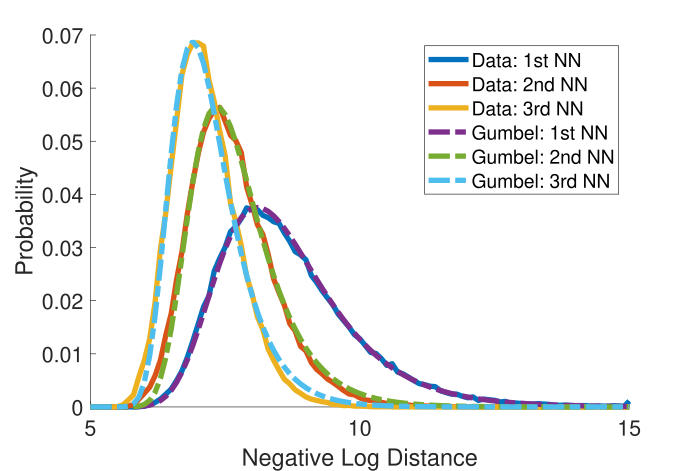
point cloud completion, can be accurately modeled using Gumbel distributions. We
validate our method on tasks like few-shot image classification and 3D point cloud
completion, demonstrating significant improvements over state-of-the-art loss functions across several benchmark datasets.
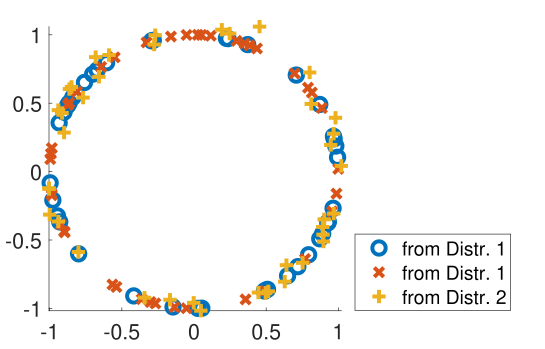
Figure 1: Illustration of three point sets randomly sampled from a circular distribution (i.e., Distr. 1) and a Gaussian whose mean is conditional on the circle (i.e., Distr. 2)
Figure 2: Data fitting with Gumbel distributions for 1st, 2nd, 3rd smallest distance distributions between two 2D point sets
Introduction
$\textbf{Problem Statement}$ Set-to-set matching involves comparing and identifying correspondences between two sets of items, which can be modeled as a bipartite graph matching problem. In this framework, the items
in each set are represented as nodes on opposite sides of a bipartite graph, with the edges representing the correspondences. This task is challenging due to several factors:
(1) The matching process must be invariant to the order of both the sets and the items within them; (2) Finding effective representations for each set is critical, as it greatly influences
performance; (3) Computing a meaningful similarity score between sets, often used as a loss function for learning feature extractors, is a nontrivial problem.
Our goal is to develop a similarity measure that is both effective and efficient for set-to-set matching.
$\textbf{Limitations of Traditional Distance Metrics}$ Existing metrics fail to adequately capture the similarity between sets in terms of their underlying distributions. In many real-world
applications, such as classification, the primary concern is not the direct similarity between individual data instances but rather their similarity in some (latent) space, such as class labels.
For instance, in Figure 1 in the context of Chamfer Distance (CD), the distance between the sets $\circ$ and $+$ is larger than that between the sets $\circ$ and $+$, despite
$\circ$ and $\times$ being sampled from the same underlying distribution. This highlights a issue: $\textit{how likely are two sets of points to come from the same distribution?}$
CD and similar metrics may fail to reflect distributional similarity accurately. Consequently, traditional distance metrics are effective at measuring differences in observations (\eg point clouds or images)
but may struggle to capture deeper, potentially unknown $\textit{abstractions}$ such as distributions or class labels.
$\textbf{Our Approach and Contributions}$ We propose a novel probabilistic method for set-to-set matching called GPS (Gumbel Prior Similarity) based on distributional similarity and Gumbel
distributions. This method measures the similarity between the underlying distributions generating the sets. Specifically, we use the log-likelihood of Gumbel distributions as our similarity
measure, modeling the distributions of negative-log distances between the KNNs of the sets. GPS can be seamlessly integrated into existing neural network training frameworks, for instance, by
using the negative of GPS as a loss function, while maintaining the same linear computational complexity as CD. We propose a comprehensive analysis of GPS and its influence on learning behavior.
We are the first to leverage statistical information from KNNs for set-to-set matching. To demonstrate the efficacy and efficiency of GPS, we conduct extensive experiments on tasks such as
few-shot image classification and 3D point cloud completion, achieving state-of-the-art performance across several benchmark datasets.
Approach
$\textbf{Notations & Problem Definition}$ We denote $\mathcal{X}_1=\{x_{1,i}\}\sim\mathcal{P}_1, \mathcal{X}_2=\{x_{2,j}\}\sim\mathcal{P}_2$ as two sets of points (or items) that are sampled from two unknown
distributions $\mathcal{P}_1, \mathcal{P}_2$, respectively, and $K$ as the number of nearest neighbors considered for each point. Also, we refer to $|\cdot|$ as the cardinality of a set, and $\|\cdot\|$ as the
$\ell_2$-norm of a vector. Given these notations, our goal is to predict the set-to-set similarity, $\kappa(\mathcal{X}_1, \mathcal{X}_2)$, based on the conditional probability
$p(\mathcal{P}_1=\mathcal{P}_2 | \mathcal{X}_1, \mathcal{X}_2)$.
$\textbf{Gumbel Distributions}$ Recall that the Gumbel distribution is used to model the distribution of the $\textit{maximum}$ (or minimum by replacing the maximum with the negative of minimum) of a number of samples
from various distributions. Here we list the definition of a Gumbel distribution as follows: The probability density function (PDF) of a Gumbel distribution with parameters $\mu\in\mathbb{R}, \sigma>0$,
denoted as $Gumbel(\mu, \sigma)$, for a random variable $x\in\mathbb{R}$ is defined as
$p$
\begin{equation}
p(x) = \frac{1}{\sigma}\exp\{-(y + \exp\{-y\})\}, \; \text{where} \; y = \frac{x - \mu}{\sigma}.
\end{equation}
$\textbf{Distributional Signatures}$ Given two sets of points $\mathcal{X}_1, \mathcal{X}_2$, we define the set of Euclidean distances from each point in one set to its KNNs in the other set as their distributional signature:
\begin{equation}
\mathcal{D}(\mathcal{X}_1, \mathcal{X}_2) = \left\{d_{min}^{(k)}(x_{1,i}) = \|x_{1,i} - x_{2,i_k}\|, d_{min}^{(k)}(x_{2,j}) = \|x_{2,j} - x_{1,j_k}\| \mid \forall k\in[K], \forall i, \forall j \right\}
\end{equation}
where $i_k$ ($\textit{resp}$ $j_k$) denotes the index of the $k$-th nearest neighbor in $\mathcal{X}_2$ ($\textit{resp}$ $\mathcal{X}_1$) for $x_{1,i}$ (\resp $x_{2,j}$), leading to an unordered set of $K(|\mathcal{X}_1| + |\mathcal{X}_2|)$ values.
$\textbf{Probabilistic Modeling}$ To compute GPS, we introduce the Gumbel distributions and distributional signatures as latent variables, as shown in, and propose a probabilistic framework as follows:
\begin{equation}
p(\mathcal{P}_1=\mathcal{P}_2 \mid \mathcal{X}_1, \mathcal{X}_2)
= \sum_{q\in\mathcal{Q}}\sum_{d_{min}\in\mathcal{D}} p(\mathcal{P}_1=\mathcal{P}_2, q, d_{min} \mid \mathcal{X}_1, \mathcal{X}_2) \\
= \sum_{q\in\mathcal{Q}}\sum_{d_{min}\in\mathcal{D}} p(q)p(\mathcal{P}_1=\mathcal{P}_2 \mid q) p(d_{min} \mid q, \mathcal{X}_1, \mathcal{X}_2),
\end{equation}
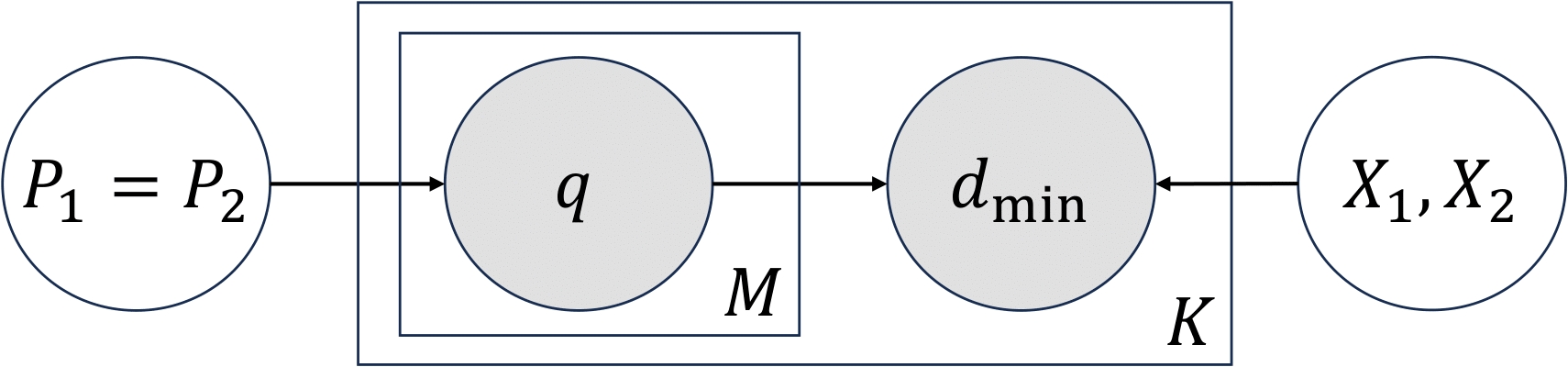
where $q\in\mathcal{Q}$ denotes a Gumbel distribution. Figure 3 illustrates the probability decomposition where a Gumbel distribution $q$
is selected for measuring set-to-set similarity based on the distributional signatures between sets. Note that the distributions of each $k$-th nearest neighbor
distances could be modeled using a mixture of $M$ independent Gumbel distributions.
Figure 3: Graphical model for computing the conditional probability $p\big(\mathcal{P}_1=\mathcal{P}_2 \mid \mathcal{X}_1, \mathcal{X}_2\big)$.
Consequently, the above equation can be further rewritten as follows:
\begin{equation}
p(\mathcal{P}_1=\mathcal{P}_2 \mid \mathcal{X}_1, \mathcal{X}_2) \propto \sum_{k, m} \left[\sum_i p\left(d_{min}^{(k)}(x_{1,i}); \alpha_{k,m}, \beta_{k,m}\right) + \sum_j p\left(d_{min}^{(k)}(x_{2,j}); \alpha_{k,m}, \beta_{k,m}\right)\right],
\end{equation}
where $k\in[K], m\in[M]$ and $\{\alpha_{k,m}, \beta_{k,m}\}$ denote the predefined Gumbel parameters of the $m$-th mixture for fitting the $k$-th nearest neighbor distances. For simplicity, we use the same mixture for both sets
(but they can be different). Note that here we take $p(q)$ and $p(\mathcal{P}_1=\mathcal{P}_2 \mid q)$ as two constants with no prior knowledge.
$\textbf{Reparametrization with Minimum Euclidean Distances}$ The KNN distances are sets of (conditional) minima, not maxima. Therefore, we need to convert these minimum distances to some form of maximum values that can be modeled using Gumbel.
Considering both computational complexity and learning objectives, we propose reparametrizing $x \stackrel{def}{=} -\log (d_{min} + \delta)$, where $\delta\geq0$ denotes a distance shift, and write as follows, which formally defines our GPS:
\begin{align}
& \hspace{-1mm}\kappa(\mathcal{X}_1, \mathcal{X}_2) \nonumber \\
& \hspace{-1mm}\stackrel{def}{=} \sum_{k,m}\left[\sum_i D_{min}^{(k,m)}(x_{1,i})\exp\{- D_{min}^{(k,m)}(x_{1,i})\} + \sum_j D_{min}^{(k,m)}(x_{2,j})\exp\{- D_{min}^{(k,m)}(x_{2,j})\}\right],
\end{align}
where $\mu_{k,m} = \frac{\log\alpha_{k,m}}{\beta_{k,m}}$, $\sigma_{k,m} = \frac{1}{\beta_{k,m}} > 0$, $\alpha_{k,m} = e^{\frac{\mu_{k,m}}{\sigma_{k,m}}} > 0$, $\beta_{k,m} = \frac{1}{\sigma_{k,m}} > 0$,
$D_{min}^{(k,m)}(x_{1,i}) = \alpha_{k,m}\Big[d_{min}^{(k,m)}(x_{1,i}) +\delta_{k,m} \Big]^{\beta_{k,m}}, D_{min}^{(k,m)}(x_{2,j}) = \alpha_{k,m}\Big[d_{min}^{(k,m)}(x_{2,j}) + \delta_{k,m}\Big]^{\beta_{k,m}}$, respectively.
BibTeX
@inproceedings{zhanggps,
title={GPS: A Probabilistic Distributional Similarity with Gumbel Priors for Set-to-Set Matching},
author={Zhang, Ziming and Lin, Fangzhou and Liu, Haotian and Morales, Jose and Zhang, Haichong and Yamada, Kazunori and Kolachalama, Vijaya B and Saligrama, Venkatesh},
booktitle={The Thirteenth International Conference on Learning Representations}
}